Text Analysis
for Oriental Languages
Discover our lemmatization, POS-tagging and morphological engine for Eastern and Classical Armenian, Old Georgian, Syriac and Ancient Greek.
Discover our lemmatization, POS-tagging and morphological engine for Eastern and Classical Armenian, Old Georgian, Syriac and Ancient Greek.
Specific text analysis for Eastern and Classical Armenian, Old Georgian, Syriac, Ancient Greek thanks to the combinaison of our ruled-based and IA models.
Calfa takes charge of the processing of your corpus, even if it contains millions of forms to be analysed.
Our IA engine backed by Calfa Dictionaries can analyse words in context for a precise and safe data annotation.
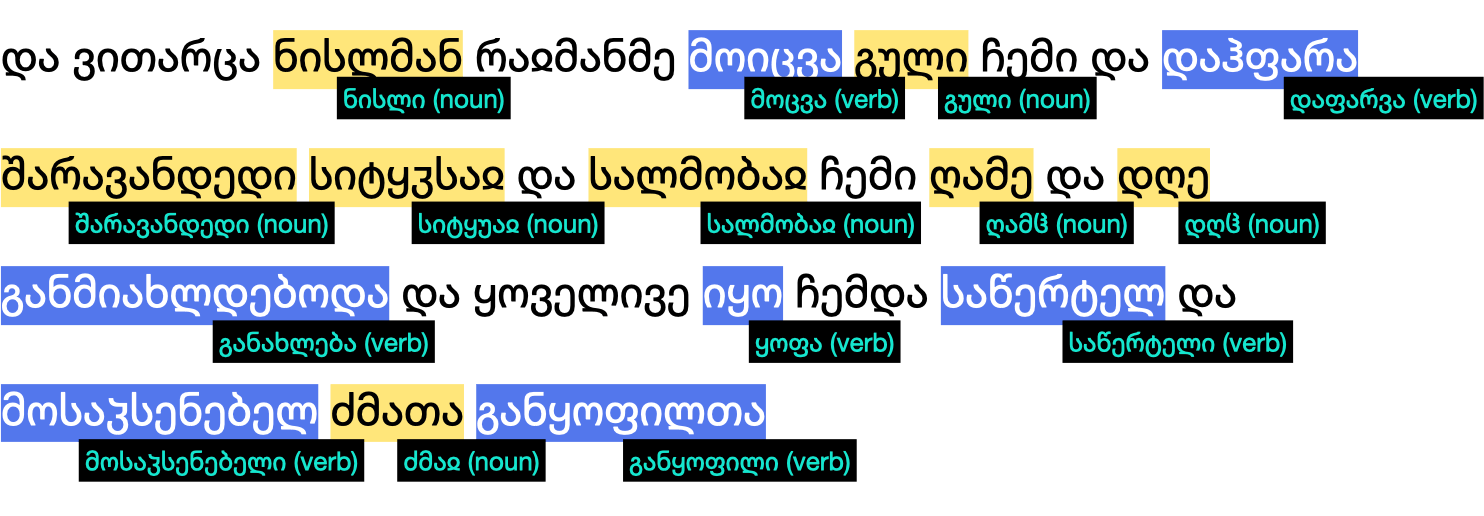
Configure the engine to use specific tag sets, on different levels : lemma, part of speech, morphological.
Softwares, linguistic data and tagged corpus for ancient GREek and ORIental languages.
EANC is a comprehensive linguistic database of annotated texts in Standard Eastern Armenian (SEA).
Digital Library of Armenian Literature of the American University of Armenia.
Text and Concordance of the 1895 Bible in Classical Armenian, with word-by-word grammatical parsing and English gloss.
Send us texts elements to get a demonstration of the analysis on your documents
Contact us for a demoLearn more
Chahan Vidal-Gorène and Bastien Kindt, Lemmatization and POS-tagging process by using joint learning approach. Experimental results on Classical Armenian, Old Georgian, and Syriac. In Proceedings of LT4HALA 2020 - 1st Workshop on Language Technologies for Historical and Ancient Languages, pp. 22–27, Marseille, France, May 2020. European Language Resources Association (ELRA).
PDF BibTeX
Chahan Vidal-Gorène, Victoria Khurshudyan, and Anaïd Donabédian. Recycling and Comparing Morphological Annotation Models for Armenian Diachronic-Variational Corpus Processing. in Proceedings of the 7th Workshop on NLP for Similar Languages, Varieties and Dialects, pp. 90-101, Barcelona, Spain, Dec. 2020. International Committee on Computational Linguistics (ICCL).
PDF BibTeX
Kindt, Bastien, Chahan Vidal-Gorène, and Saulo Delle Donne. Analyse Automatique Du Grec Ancien Par réseau De Neurones. Évaluation Sur Le Corpus De Thessalonica Capta. in Bulletin De l’Académie Belge Pour l’Étude Des Langues Anciennes Et Orientales BABELAO 10-11, pp. 537-62, UCLouvain, Fev. 2022.
PDF BibTeX